OpenAIが、日本時間2025年2月3日の朝9時に、ChatGPTの新機能「Deep Research」に関するライブストリームを実施した。
「Deep Research」機能は、o3のカスタムモデルが、最大で30分もの長時間をかけてWeb検索を自動で行い、アナリストやリサーチャーが作成するレベルのリサーチペーパーを生成してくれる、と言う画期的な機能だ。
Google Geminiでも、「Deep Research」機能(参照:解説記事)として実装されていたものが、OpenAIのChatGPTでも実装された格好になる。
ChatGPT Proプラン向けに、今日中(2月3日中)に利用可能になり、Plus/Teamsプランには近々実装予定とのことだ。
本記事では、つい先ほど行われたOpenAIによるライブ配信とニュースリリースについて、概要をまとめた。
ChatGPT新機能「Deep Research」の概要
OpenAIが発表した「Deep Research」は、従来のChatGPTが即時に答えを返す方式とは異なり、最大30分かけてWeb上の情報を集め、専門家が作成するようなリサーチペーパーを自動生成する機能だ。
ライブ配信の中で紹介された、Deep Researchの概要は以下の通りである。
- マルチステップの自律リサーチ
- o3をファインチューニングしたモデルを基盤として、複数のステップに分けてWeb情報を収集してくれる。
- ページの読み込み、画像、表、PDFなどあらゆるデータを解析し、必要に応じてリサーチプランを修正する。
- 確認質問で要件を明確化
- ユーザーからの質問に対し、まず確認の質問を返し、間違った方向で数分間リサーチしてしまうことを防ぐ。
- 統合レポートの自動生成
- 収集した情報をもとに、引用元を明示したリサーチペーパーを作成する。
- Pythonツールを利用した計算や、画像・グラフの生成、埋め込みも可能。
アナリストやリサーチャーが作成するような非常に質の高いリサーチペーパーを、ChatGPT上で自動で生成できてしまうというのだ。
Pythonを使ったグラフの生成とレポートへの埋め込みまで可能ということで、もはや大半の人類より優秀なリサーチャーと言えるかもしれない。
ただ、Deep Researchは非常に計算量が多いので、Pro版のユーザーであっても利用回数に制限があるようだ。
OpenAIのニュースリリースおよびサムアルトマン氏のXでのポストによれば、現在のバージョン(o3モデルを使用)の使用回数制限は、以下の通りだ。
- Pro:月100回
- Plus/Team:およそ月10回の見込み
- Free:利用回数は非常に少ないが実装予定
将来的には、o3-miniなど小型モデルを活用し、より計算量の少ないバージョンも計画しているとのことだ。
Deep Researchを使ったレポート生成の流れ
本日行われたライブ配信「Introduction to Deep Research」では、マーケットリサーチで「Deep Research」を活用する例を示しながら、使用方法が示された。
以下のようなプロンプトを、ChatGPTの画面上で「Deep Research」ボタンをオンにした状態で与える。

以下はデモで使用された実際のプロンプトと、その日本語訳だ。
Help me find iOS and android adoption rates, % who want to learn another language, and change in mobile penetration, over the past 5 years, fortop 10 developed and top 10 developing countries by GDP. Lay this info out in a formatted report, a table on metrics, and include recommendations on markets to target for a new translation app from ChatGPT, focusing on markets ChatGPT could better expand into.
(iOSとandroidの普及率、他の言語を学びたい人の割合、過去5年間のモバイル普及率の変化を、GDPで先進国トップ10と発展途上国トップ10で見つけるのを手伝ってください。また、ChatGPTの新しい翻訳アプリのターゲットとなる市場に関する推奨事項を含めてください。)すると、ChatGPTがリサーチを開始する前に、いくつかの確認質問を返答してくる。
Deep Researchは、完了するまでに数十分かかることもあるので、最初にユーザーの希望を明確化しておかなければ、時間を無駄にする可能性が高いため、このような確認ステップがある。
ここでは、人口は割合と実数どちらが必要か、「言語を学びたい」ことをどう定義するか(一般的関心か、既に学習中か)など、レポート作成に必要になりそうなポイントを、ChatGPTが質問してきている。

Deep Researchが始まると、進捗バーが表示される。ここから5〜30分待機することになるが、進捗中に他のスレッドを見たり、別の画面に移動していても問題ないようだ。
画面右側には、o3がどのような思考ステップを踏んで、リサーチを実行しているか、進捗が表示される。
Web検索を行って、結果について思考し、またWeb検索を行う、というマルチステップでのリサーチの様子が見て取れる。

レポートが完成すると、PDFなどが生成されるわけではなく、チャット内にMarkdown形式でレポートが書き出される。
画面右側では、このレポートに使用されたすべての引用ソースが表示される。
レポート本文には、1文1文にソースとなるリンクが明示されているので、AIが生成した内容が正しいかどうか、ユーザーがクリックして原典を確かめることができる。
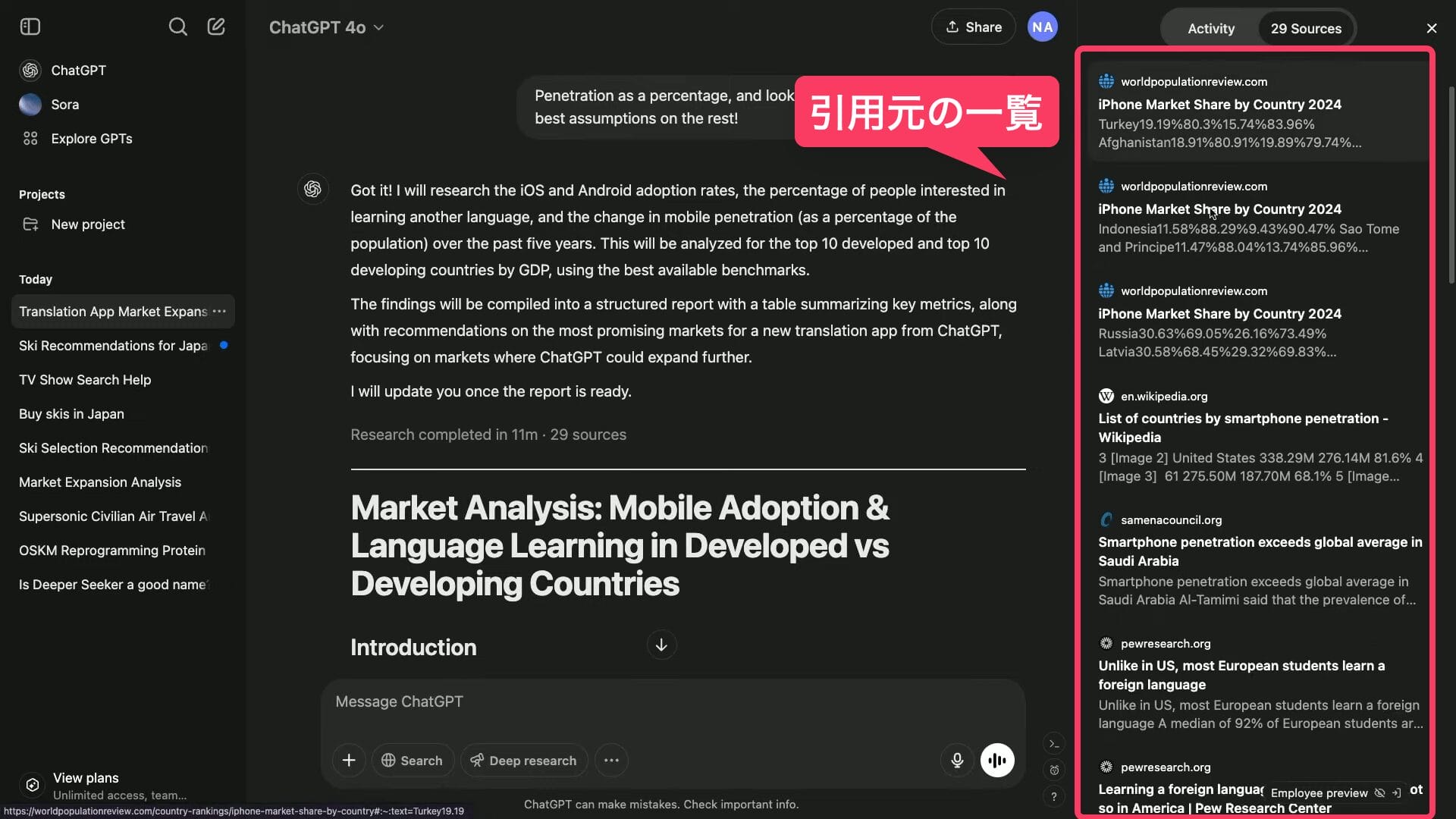
レポート内では、テキストだけでなく、表なども活用されている。

様々な分野でのDeep Researchの活用例
Deep Researchは、かなり実用できる場面が多いので、人々の検索行動を変えてしまう可能性もありそうだ。
例えばビジネスシーンでは、投資分析、市場調査、学術研究など、専門的な情報収集が求められる場面で、膨大なWeb情報から必要なデータを抽出し、短時間で詳細なレポートを生成することができる。
社員1人が、ChatGPTを活用することで、従来は到底できなかったような仕事量をこなすことができてしまう。
また、私生活でも、商品の購入検討時、複数のレビューサイトや比較情報を調査し、表やグラフを含むレポートを自動生成するなど、普段Web検索を自力でやっていることを、ChatGPTに委ねることができるようになる。
ライブ配信の中でも、ビジネスから個人の買い物など、幅広いシーンでDeep Researchを活用する例が紹介されていた。
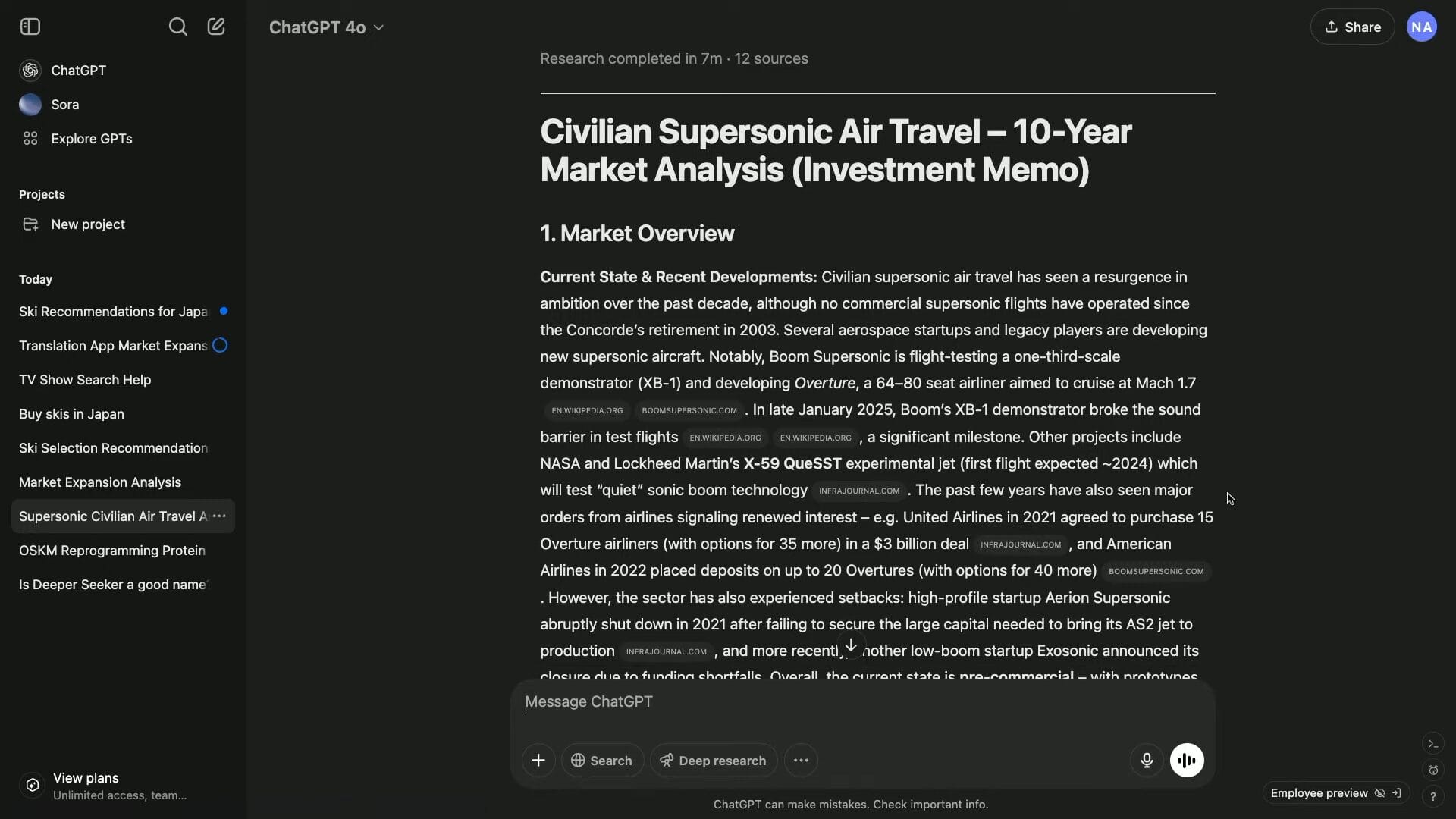
ベンチャーキャピタルの投資メモを作成する
たとえば、シリコンバレーのVCファーム向けに民間超音速旅客機市場の投資メモを作成する例が示された。
実際に、7分間のリサーチを行った上で、詳細なレポートを生成してくれた。
類似論文・先行研究のリサーチ
アカデミックな分野でも、Deep Researchはかなり役に立ちそうだ。
ライブ配信では、生物学の論文を1つアップロードして、これと似た論文を探索せよ、という指示を与えた例が示された。
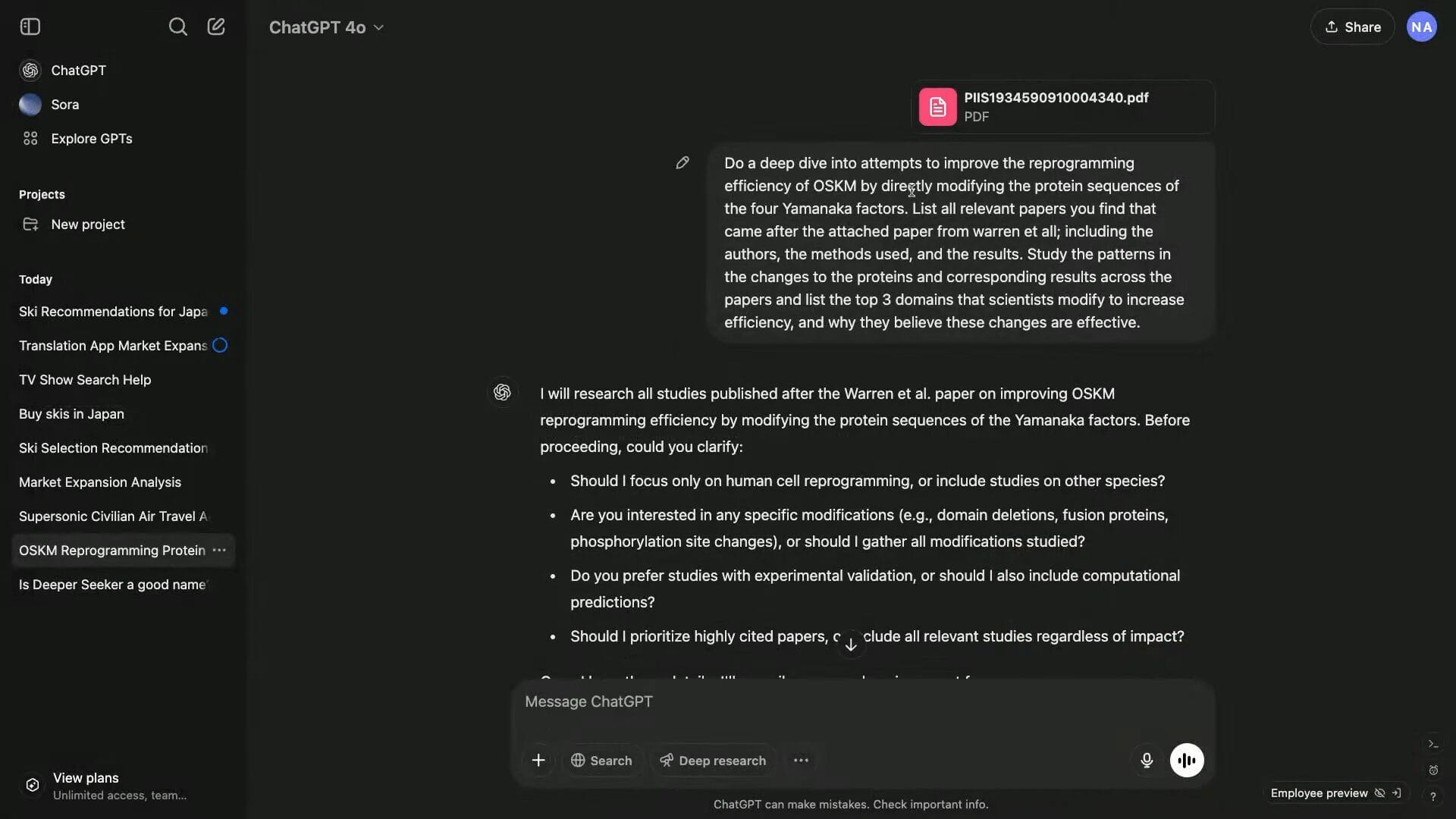
すると、ちゃんと先行研究をサマリーしたレポートが生成された。
OpenAIの生物学を専攻する職員によれば、レポートの完成度はかなり高いらしい。
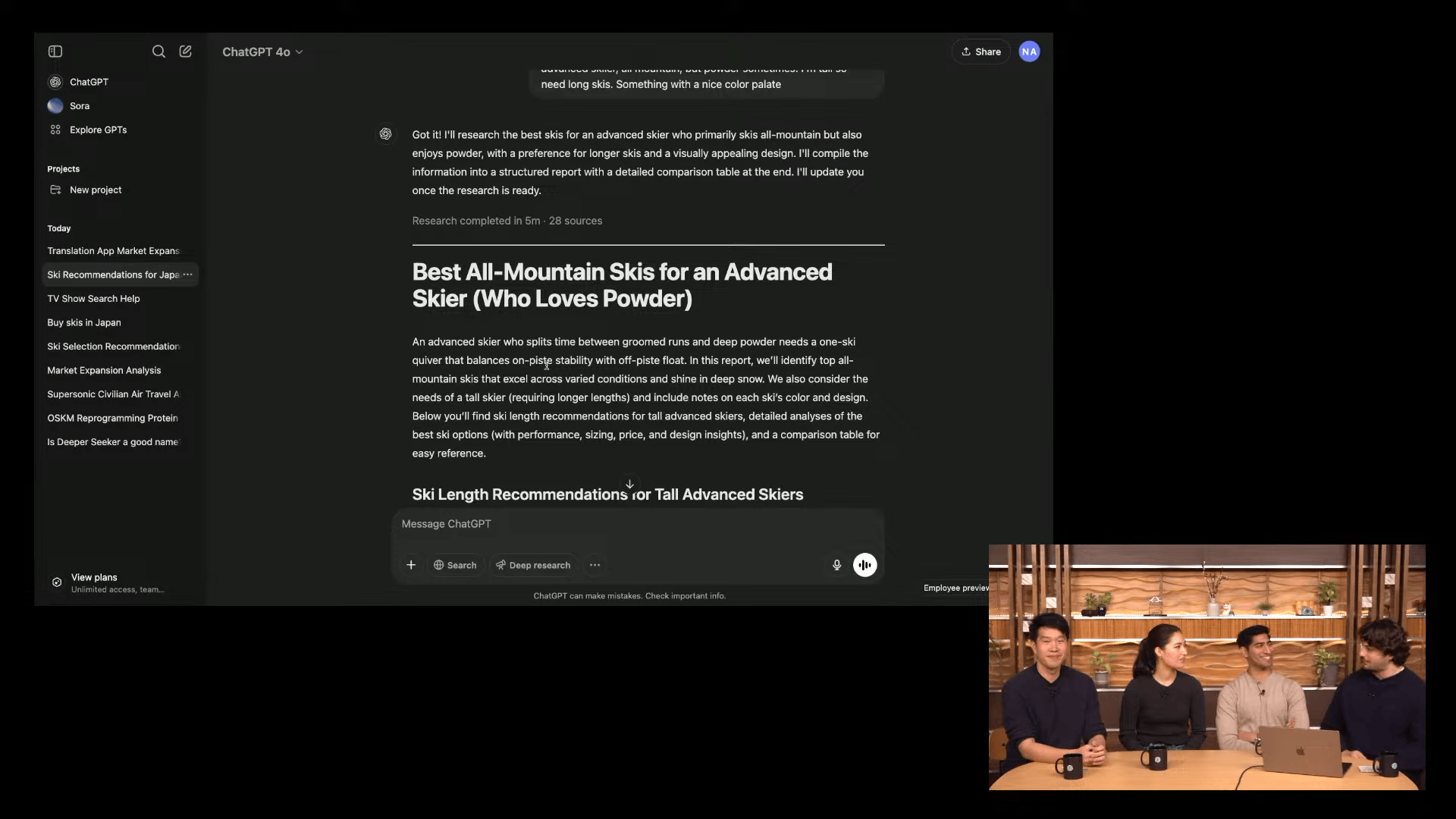
日本で購入するスキー用具の候補探索
今回のOpenAIのライブ配信は、珍しく東京から行われていたので、日本の文脈に合わせたデモンストレーションも行われた。
個人で何か買い物をしたいときに、レビューサイトの閲覧や、候補となる商品の比較表の作成などを、ChatGPTにやらせてしまおうという例だ。
デモでは、スキー用具の購入について、自身のスキーのレベルやスタイルを伝えることで、候補となる商品をChatGPTに挙げてもらっていた。
曖昧な記憶から、過去に視聴したTV番組を特定する
過去に見たTV番組のエピソード名の特定など、非常にニッチな用途もデモンストレーションされた。
断片的で曖昧な記憶から、複数の情報源から、その条件を満たすテレビ番組を特定するというリサーチだ。

こうしたリサーチ作業は、キーワードの特定が難しいため、通常は非常に手間がかかりそうなものだが、AIを活用すれば、何通りものクエリを試し、ユーザーの掲示した条件を満たすものを特定してくれるので有意義だ。
o3 + Deep Researchで各種ベンチマークも改善
ただでさえ非常に性能の高い推論モデルであるo3だが、Deep ResearchとPythonツールを装備することで、さらに強力なモデルとして問題解決能力が向上している。
以下は、最新のベンチマークテストである「Humanity’s Last Exam (HLE)」 の結果を、現存のフロンティアモデルについて整理したものだ。Deep Researchを有効にしたo3モデルは、圧倒的に高い正答率を誇っている。
| Model | Accuracy (%) |
|---|---|
| GPT-4o | 3.3 |
| Grok-2 | 3.8 |
| Claude 3.5 Sonnet | 4.3 |
| Gemini Thinking | 6.2 |
| OpenAI o1 | 9.1 |
| DeepSeek-R1 | 9.4(モデルが画像非対応のためテキスト問題のみ) |
| OpenAI o3-mini (medium) | 10.5(モデルが画像非対応のためテキスト問題のみ) |
| OpenAI o3-mini (high) | 13.0(モデルが画像非対応のためテキスト問題のみ) |
| OpenAI Deep Research (o3 + Browsing + Python) | 26.6 |
HLEは、従来用いられてきたベンチマークテスト(MMLUなど)では、GPT-4o, Claude, Gemini, Grokなど各社のLLMが容易に90%を超えるようになってしまっている中、さらにハイレベルなLLMの評価を可能とするために開発されたベンチマークだ。
数学、人文科学、自然科学など、数十の学術分野にわたる3,000問の問題で構成される。約1000人の専門家によって作成され、各問題は、インターネット検索だけでは解決できない設計となっている。
GPT-4o、Grok-2、Claude 3.5 Sonnet、Gemini Thinkingなどの最先端モデルでさえ、HLEでの正確性は10%未満にとどまっている。Deep Researchのように、Web検索やPythonコードなどツールをモデルに統合することで、大幅にパワーアップできることが示唆されている。
また、Web検索やツール機能を備えたAIモデル同士を比較する最新のベンチマークであるGAIA (General AI Assistants)の結果も紹介されている。
GAIAは、実世界の問題解決能力に焦点を当て、推論、マルチモーダル処理、ウェブ検索、ツール使用能力など、モデルの総合力を評価するベンチマークだ。
466問の質問で構成され、テキストベースの質問に加え、画像やスプレッドシートなどのファイルを含むことがある。複数のツールを組み合わせた問題解決能力が必要とされる。
| モデル | Level 1 | Level 2 | Level 3 | Avg. |
|---|---|---|---|---|
| 従来の最高記録 | 67.92 | 67.44 | 42.31 | 63.64 |
| Deep Research (pass@1) | 74.29 | 69.06 | 47.6 | 67.36 |
| Deep Research (cons@64) | 78.66 | 73.21 | 58.03 | 72.57 |
「pass@1」は最初の1回の回答でのパフォーマンス、「cons@64」は64個の回答候補から多数決で最終的な回答を決定した際のパフォーマンスである。
ChatGPTのDeep Researchは、GAIAでも最高記録を叩き出しており、Web検索やコードツールを利用できる他のモデルと比べても、o3 + Deep Researchが、トップレベルの能力を有していることが示されている。
「エージェント」としてのAIの実現は近い
OpenAIが発表した「Deep Research」は、長時間にわたる自律的なWebリサーチを実現し、瞬時に答えを出す従来型AIとは一線を画す技術だ。
OpenAIは、この機能を、「エージェント」が長時間かけて自律的に複雑なタスクを解決する未来への第一歩と位置付けている。
将来的には、サブスクリプションが必要なメディアやデータベースとの接続や、企業内データとの連携など、さらに高度なリサーチエージェントの実現も目指しているとのこと。
自社のデータベースを、AIが「Deep Research」して、四半期レポートや、今後の事業展開のアイディアなどをレポーティングしてくれるような世界が、数年以内には実現してしまうかもしれない。
また、すでにChatGPT Proに実装されている「Operator」は、ブラウザの自律的操作も可能なため、Deep ResearchとOperatorを組み合わせて、さらに高度なタスクを実現するエージェント機能についても、実現の時期は明らかでないが、ビジョンが言及されている。
