
OpenAIは2025年3月25日、ChatGPTで使えるGPT-4oモデルをアップデートし、ネイティブ画像生成機能「4o Image Generation」をリリースした。
これまでもChatGPT上で画像生成自体は可能だったが、外部の画像生成専用のAIモデル「DALL-E」を呼び出していただけだった。
今回の「4o Image Generation」は、言語モデルでもあるGPT-4o自身が、直接、画像を生み出せるようになったのが特徴だ。
したがって、MidjourneyやStable Diffusion、DALL-Eなどの従来の「画像生成専用」のAIモデルでは不可能だったような、正確な文字の描写や、細かい指示の完璧な再現が可能になっている。
実際に使ってみたところ、凄まじい精度で思った通りの画像を生成でき、かなり衝撃的だ。IPが弱いイラスト制作やグラフィックデザインの仕事は、駆逐されてしまうのではないかという恐怖すら感じる。
既存の画像の編集や一部変更、同一のキャラクターの維持、透明レイヤーのベクターイメージの生成など、幅広い機能を備えており、趣味の世界を超え「業務で使えるレベル」に到達している。
本記事では、「4o Image Generation」で可能になった全ての新機能を、サンプルとともに詳しく解説する。この記事を参考に、ぜひ試してみてほしい。
「GPT-4o」と「4o Image Generation」の概要
「4o Image Generation」は、ChatGPTで利用できるAIモデル「GPT-4o」に組み込まれた画像生成機能である。リリース当日中にChatGPTのPlus、Pro、Teamユーザー向けにロールアウトが概ね完了したとみられ、近々、無料ユーザーでも利用可能になる予定だという。
ChatGPTにアクセスして、モデルセレクタで「ChatGPT 4o」を選択した状態でチャットしていると、画像を生成する必要がある場面で、自動的に画像ジェネレーターが起動される。

GPT-4oは、「マルチモーダル」なAIモデルとされる。「マルチモーダル」とは、文字・画像・音声など様々な媒体のインプット/アウトプットが可能であることを意味する。
つい最近、GPT-4oモデルでの音声の文字起こしや、テキストの読み上げが可能なGPT-4oの音声機能がリリースされているが、音声機能もマルチモーダルの恩恵の一つだ。
「4o Image Generation」は、そんなGPT-4oのマルチモーダルの強みを活かした画像生成機能だ。
GPT-4oは、テキストと画像の関係だけでなく、画像同士の関係性も理解できるようにトレーニングされている。そのため、テキストの指示で画像を生成させるのはもちろん、画像を見せて似た画像を生成させたりすることもできる。
また、生成するイラストの中に、GPT-4oが持っている知識を反映することも可能だ。例えば、以下は「平均値」について解説するコミックを、GPT-4oに描いてもらった例だ。
単にイラストを描くのではなく、イラストを使った概念の解説まで可能なので、他の画像生成AIとは全く異質の存在と言える。

ChatGPT「4o Image Generation」で出来ることまとめ
「4o Image Generation」は、従来の画像生成モデルが苦手としていた分野で、凄まじい改善を実現している。
テキストを含む画像の生成から、人物・キャラクターの同一性の維持、透過レイヤーの生成など、ビジネス業務で実用できるレベルの機能群を備えているので、その使い方を一つ一つ解説していく。
プロンプトの追従性(指示を守ること)がとにかく優れており、思った通りの生成や編集が可能なので、本当に革命的だ。
GPT-4oによるテキスト入りのロゴ・イラストの生成
DALL-EやMidjourney、Stable Diffusionなどの画像生成モデルは、イラストの生成には長けているが、イラストの中でテキストを生成する能力に欠けているのが課題だった。
そのため、社名ロゴのタイポグラフィや、文字を含むポスターのデザインなどは、従来の画像生成AIではほぼ不可能だったと言っても過言ではない。
それに対して、GPT-4oによる画像生成は、画像内でテキストを正確に描写する能力が大幅に向上している。
ウェブ広告用のバナー画像の制作、会社のロゴの制作、インフォグラフィック・マンガ・ポスターの制作など、テキスト情報が重要なデザイン作業時に非常に役立つ。
4o Image Generationでテキストを含む画像を生成する方法は非常にシンプルで、ChatGPTとのチャットの中で、画像に含むべきテキスト情報を伝えるだけで良い。
例えば、以下のようなプロンプトを与えてみると、見事に「Cheese Burger」という文字と、「$4.99」という価格情報が描写された。
ニューヨークのビル街にある大きい看板で、チーズバーガーを宣伝する広告。$4.99という価格が表示されている
GPT-4oによる一貫性のあるシーン・人物・キャラクターの描写
ChatGPTは、同一スレッド内のチャット履歴や画像履歴を記憶しているので、それらと一貫性を保ちながら、画像の一部を修正したり、同じイラストを別の視点から見たバージョンを生成したり、ストーリーを展開させたりすることができる。
また、既存の写真やイラストを読み込んで、内容を理解した上で、それに基づく新たな画像を生成できる。
サンプルとして、女性の写真を用意して(Midjourneyで生成)、この人物が様々な行動をするシーンの描写に挑戦してみよう。

まずは、この人物を維持しながら、アスペクト比の変更、シーンの変更を行ってみる。
この写真を、横長のポートレート写真とし、背景を人のいない東京の渋谷の交差点にしてください。背景が「人のいない渋谷交差点」というかなり特殊なシナリオなので、難易度が高い指示のように思えるが、以下のようにバッチリ注文通りに生成してくれた。
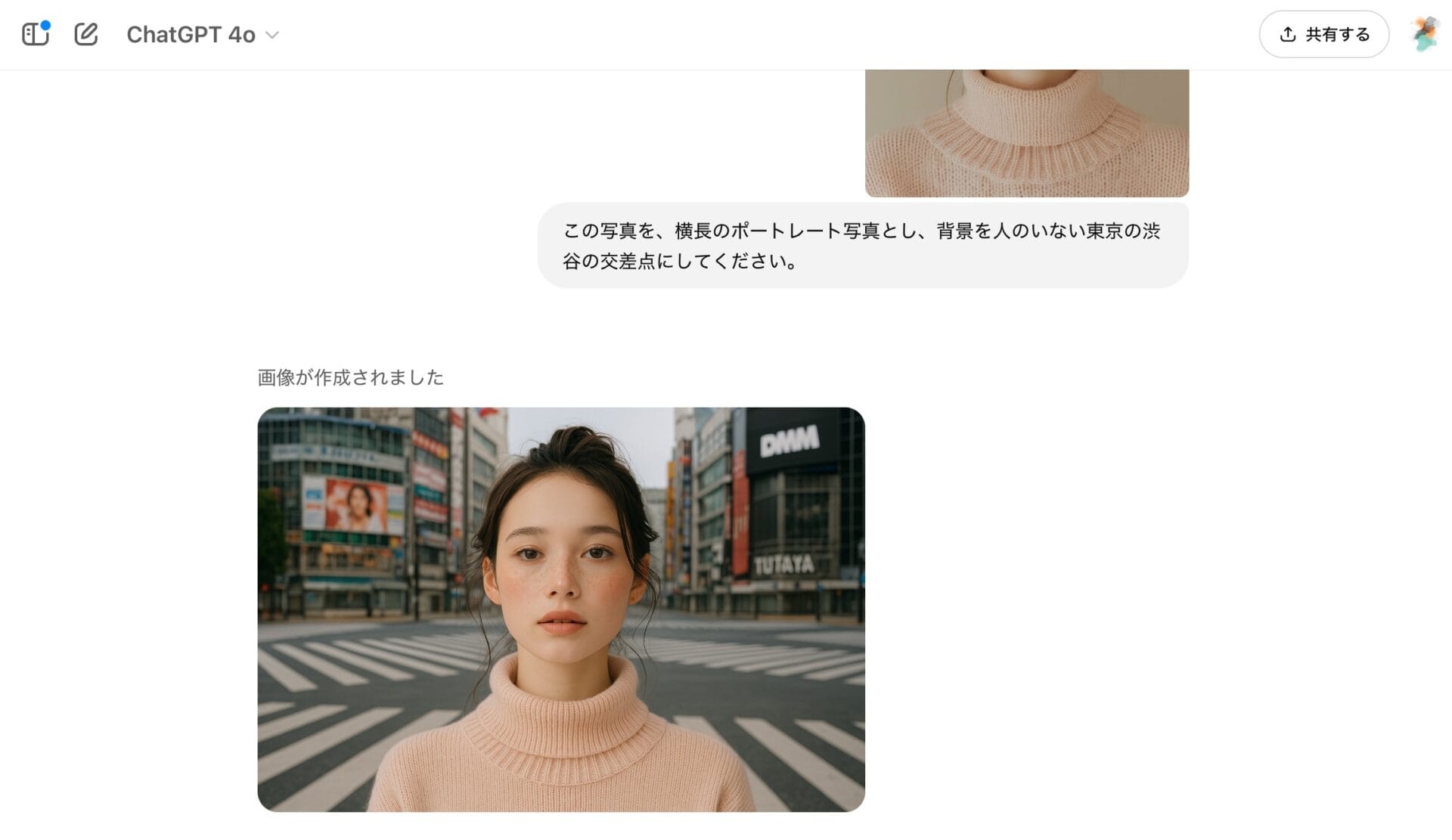
人物の顔や服装も、ほぼ完璧に維持されている。ここまでキャラクターの維持が可能であれば、自分で撮影したセルフィーの背景を、GPT-4oで別の場所に変更する、なんて用途でも使えそうだ。
さらに、もはや写真ですらなく、空想上の世界にこの人物を入れてみる。
写真を水彩画風のイラストへと変換し、全く違うシーン(タンポポ畑)に移動させるという注文をしてみた結果が以下である。
この人物を水彩画を用いた写実的なイラストにして、タンポポ畑を散歩している様子を描いてください。髪の色や髪型、服の色や形、顔の特徴(頬の赤み、そばかす)がしっかりと維持された上で、水彩画っぽく変換されている。

従来の画像生成AIは、画像の一部だけを変更したくても、全体が再生成されてしまい、2回目の生成時には全く異なるイラストが完成してしまう、ということが課題だった。
GPT-4oであれば、対話的な編集能力と記憶能力によって、イラストや写真の一貫性を保ちながら、望むイメージに正確に近づけることができる。
もちろん、人物やキャラクターの描写だけでなく、ロゴやバナーのデザインを、少しずつ対話的にブラッシュアップしていくことが可能なので、実務的なデザインワークの代替も進みそうだ。
GPT-4oで複数画像をミックスし、構図や背景をトレースする
GPT-4oは、与えた画像を読み取って理解することができるので、構図や背景をテキストで指示しなくても、参考画像を見せることによって再現させることも可能だ。
例えば、先ほど生成したピンクのセーターの女性がタンポポの中に立っているイラストを、全く異なる構図のイラストに変更してみる。
参考画像として用意したのは、少女がスカイダイビングしている様子の以下のイラストである(Midjourneyで生成)。

元画像と、スカイダイビングポーズの参考画像を与えた上で、以下のようなプロンプトを与える。
ピンクのセーターの女性のイラストを、飛んでいるイラストと同じポーズと背景に変更してくださいこれだけで、完璧に構図をトレースしたイラストが生成された。元のイラストの人物の特徴を崩すことなく、ポーズと背景だけが、参考画像と同じになっている。

Stable Diffusionなどの他社の画像生成AIモデルでは、Control Netなどを導入して複雑な設定をしなければ実現できないことが、ChatGPTに画像を渡して一言指示するだけで実現できてしまうのだ。
GPT-4oで生成した画像の一部を選択・編集する
ChatGPT内で生成された画像をクリックすると、生成画像をダウンロードできるほか、画像の一部を選択する「選択ツール」を利用することができる。
生成された画像について、追加、削除、置き換えたい部分がある場合に、編集したいエリアを指定した上で、追加の修正指示をすることができる。
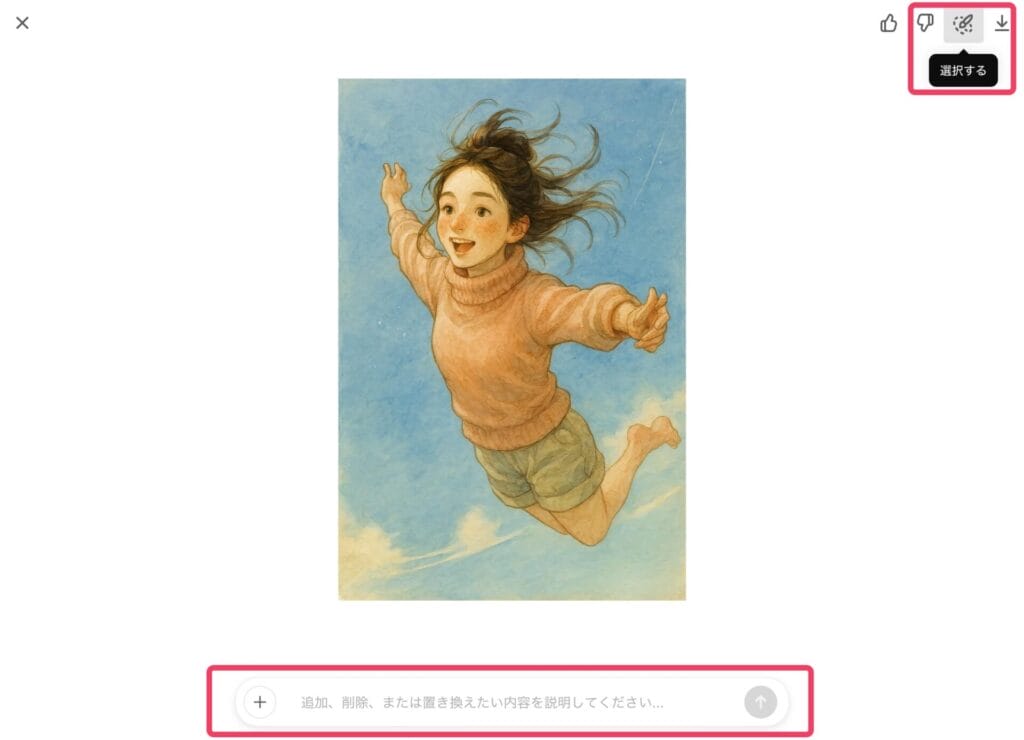
例えば、先ほど生成したスカイダイブのイラストについて、よく見ると右足が描写されておらず違和感があるので、選択ツールで下半身を選択した上で、「右足を伸ばし、左足を曲げている状態」という修正指示を行ってみた。
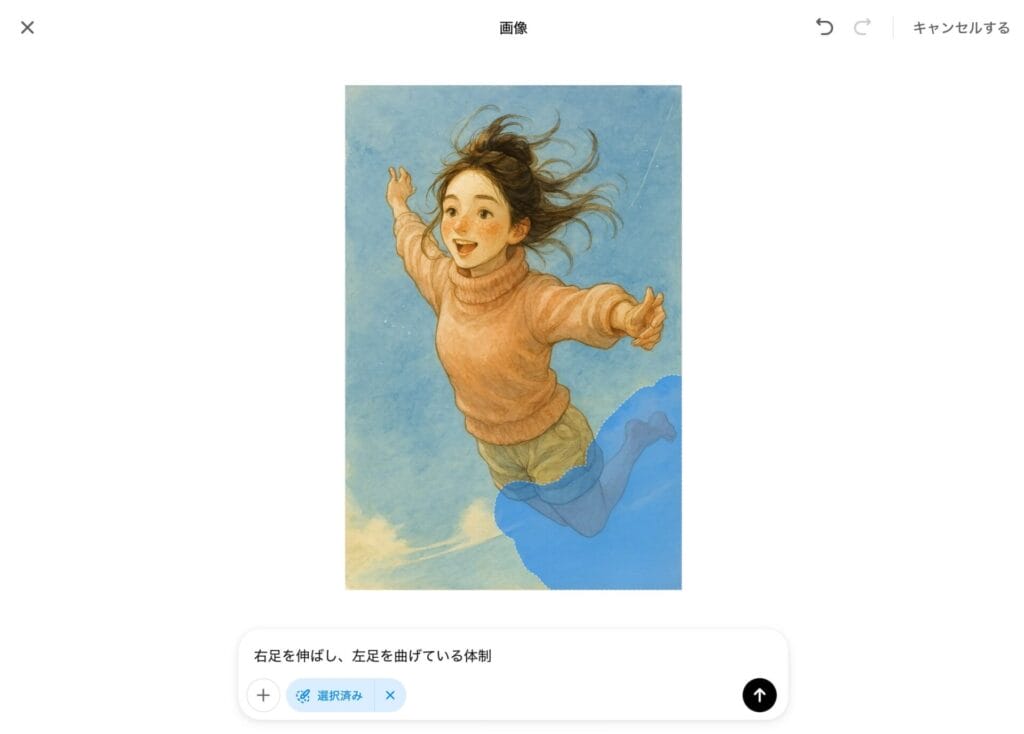
すると、GPT-4oが、選択部分と修正指示を踏まえて、再び画像生成を開始する。
生成された画像が以下で、見事に意図した通りの修正が反映され、両足が描写され、違和感のない構図にすることができた。

こうした部分修正の機能を駆使すれば、GPT-4oと対話しながら、事細かな指示を重ねていき、自分のイメージ通りの画像に少しづつ近づけていくことができる。
GPT-4oによる透過レイヤーのベクター画像の生成
4o Image Generationは、プロンプトの最後に「背景を透過してください。」と付け足すだけで、簡単に透過された.png画像を生成できる。
これによって、アイコンやバナー、ロゴなどの実用性の高いデザイン業務にも、画像生成AIが大いに役立ちそうだ。
例えば、当サイトのURLである「NotAI」という文字列を、透過ロゴとしてデザインしてもらったのが以下だ。
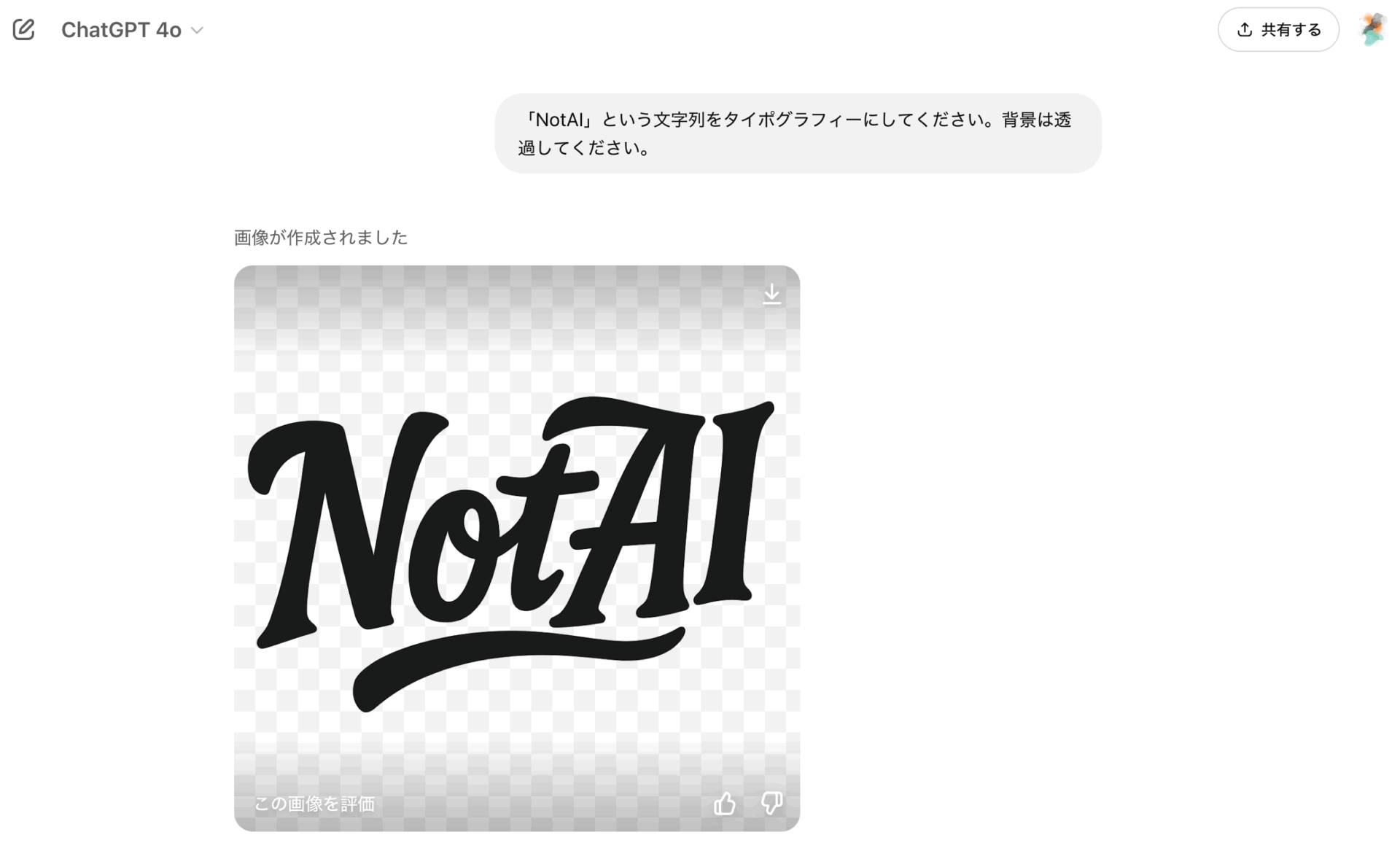
さらに、先述した一貫性のある編集機能を活かすことで、このタイポグラフィを、自分の持つロゴのイメージへと近づけていくことができる。
追加で、ロゴの周りを囲む枠をつけ、色も付けるように指示をしてみる。
タイポグラフィーをグレーの円で囲んだモダンなデザインのアイコン風にしてください。ティールとピーチの水彩風のアクセントで装飾してください。すると、先に生成したタイポグラフィーを崩すことなく、指示を的確に守りながら、アイコン風にアップデートしたpng画像を生成してくれた。

ちなみに、アスペクト比の指定、特定のヘックスコードによる色指定なども可能で、デザイン実務で十分活用できそうな完成度だ。デザインの知識が全くなくても、GPT-4oを活用すれば、ロゴやバナーの作成業務をかなり柔軟に実行できてしまいそうだ。
ここまでに登場したキャラクターの一貫性を維持する機能や、透過画像を生成する機能を組み合わせていけば、例えば自主制作ゲームの立ち絵やデモをAIに作ってもらっちゃう、なんてこともできる。
まずはキャラクターの立ち絵を様々なバリエーションで生成させる。
ファンタジーゲームに登場する魔法少女の主人公のピクセルアートを9種作成してください。いずれも戦闘シーンで利用できる様々な姿勢のバリエーションをつけてください。背景は透過してください。
そして、そのキャラクターが実際にモンスターと戦っているシーンを描写させてみる。
モンスターとの戦闘シーンのサンプルを一つ作ってください
きちんとキャラクターの一貫性が保たれた上で、透過画像の生成、通常の画像の生成を行ったり来たりできるので、非常に便利だ。
GPT-4oが持つ知識を活かした画像生成
GPT-4oが自ら画像生成してくれるので、GPT-4oが持つ広範な知識を、画像生成に活用できる。
冒頭で紹介した「平均値」の概念を解説するコミックのように、テキストベースの知識・情報(コード、レシピ、科学的概念など)を理解・解釈して、それを視覚的に表現することが可能なのだ。
人間が事細かに指示をしなくても、GPT-4o自身が何を描くべきかから考えてくれるので、インフォグラフィックやダイヤグラム、図解解説などに活かすことができる。
例えば、日本の観光ツアー会社の広告をゼロから考えてもらってみた。
日本の観光ツアー会社のバナー広告画像を生成してください。ヨーロッパから日本への観光客に人気の日本食を3つ選び、その3つをイラストで描いて、クリックを呼びかけるテキストを画像の下部に書いてください。何も具体的な指示はしていないが、GPT-4oがキャッチコピーを考案し、ヨーロッパからの観光客に人気の日本食を「寿司・ラーメン・天ぷら」と自ら判断し、それらのイラストを自主的に描いてくれている。

言語モデルの知識と画像生成能力が結びつくことで、よりアイディアの画像化・イラスト化が容易になる。
著作権フリーのイラスト・画像サイト、広告バナーの制作サービスなども、ChatGPTによってかなり需要を奪われてしまいそうだ・・・。
GPT-4oの登場で、画像生成AIの活用・応用例は激増しそう
4o Image Generationは、GPT-4oのマルチモーダル能力を活かして、ユーザー指示への追従性、テキストの描写力、背景情報や文脈の理解、画像同士の一貫性など、従来の画像生成AIの課題をほぼ全て克服した画像生成機能だ。
4o Image Generationの登場により、画像生成AIは単なる趣味やエンタメのツールから、デザイン業務などビジネスの場でも実用に耐えうる本格的なツールに進化したと言えそうだ。
あまりにも指示に忠実で、繊細な編集が可能なので、一般ユーザーにとっても従来の画像生成AIより圧倒的に使いやすいものになった。
また、透過レイヤー、カラーコード指定、一貫性の維持など、プロユースにも耐えうる機能が盛り込まれている。
- 各種デザイン業務:ロゴ、バナー、ポスターのデザインにも十分使える性能
- ロイヤリティフリー画像の代替:欲しい画像やイラストがあれば即生成、検索不要に
- ビジネスシーンでの利用:プレゼンに挿入する図解やアイコンを思い通りに生成
こうした様々なシーンでの活用が間違いなく広がるはずだ。
